データーベースの正規化
データの冗長性を減らして整合性を保つために行う。
テーブルを何も考えずに作ると、更新、削除、追加したりと、テーブルを操作する際に、いろいろと不都合が出てきてしまうので、あるべき姿(正規形)にしておきましょうという話です。
レベルは3つ(第1,第2、第3正規形)あります。第3正規形までもっていく必要があります。
第1正規形
繰り返しのある列(配列や複数の値を持つ列)を排除し、すべての属性が原子値(1つの値)であること。
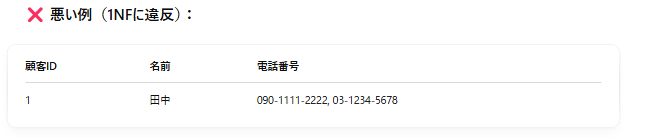
→ 電話番号が複数の値を1つの列に持っている。
上記のように、電話番号列に複数の値を入れるのもNGですが、
電話番号列が、複数列存在するのもNGです。
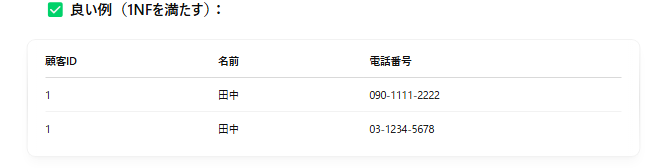
第1正規形になっていないことの問題点
一番初歩的なことができていないので、問題点は多くあります。
たとえば、「電話番号」列に複数の値があると、
「市外局番が03の番号を持つ顧客を探す」などの検索が非常に難しくなります。
第2正規形
1NFを満たしていること。
かつ、主キーの一部にしか依存しない非キー項目が存在しないこと(部分関数従属の排除)
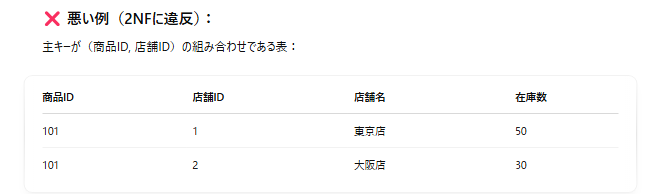
→ 「店舗名」は店舗IDのみに依存していて、主キーの一部にしか依存していない(部分関数従属)。
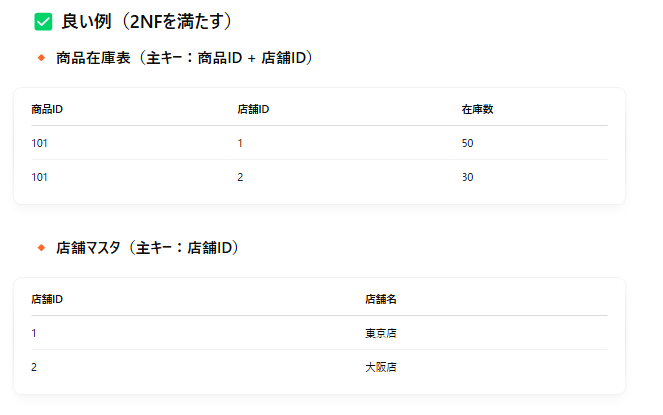
第2正規形になっていないことの問題点
① データの冗長性(無駄な繰り返し)
- 例えば、「店舗名」が複数の行に同じように繰り返されます。
例えば、「店舗名」が複数の行に同じように繰り返されます。→ データ量が無駄に多くなる。
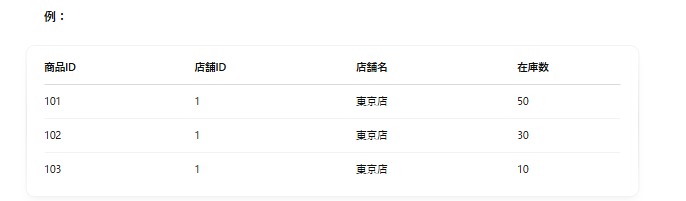
→ 「東京店」が何度も繰り返されています。
② 更新時の不整合(Update Anomaly)
- もし「東京店」の名前が「新東京店」に変わったとき、すべての行を更新する必要があります。
- 1行でも更新漏れがあると、データが矛盾します。
③ 挿入時の問題(Insert Anomaly)
- 新しい店舗を追加したいけど、まだ在庫がない場合、店舗情報を単独で登録できない。
例:
「店舗ID = 3, 名古屋店」だけ追加したいけど、商品在庫がないと登録できない構造。
④ 削除時の問題(Delete Anomaly)
- 商品をすべて削除すると、店舗情報も一緒に消えてしまう可能性がある。
例:
「東京店」が扱っていた商品がすべて売り切れてデータを削除した場合、「東京店」の情報そのものもなくなってしまう。
第3正規形
2NFを満たしていること。
かつ、非キー項目が他の非キー項目に依存していないこと(推移的関数従属の排除)。
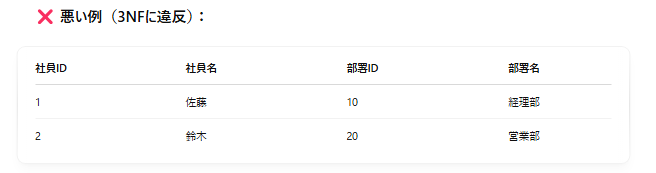
→ 「部署名(非キー)」は「部署ID(他の非キー)」に依存していて、社員ID → 部署ID → 部署名という推移的な依存がある。
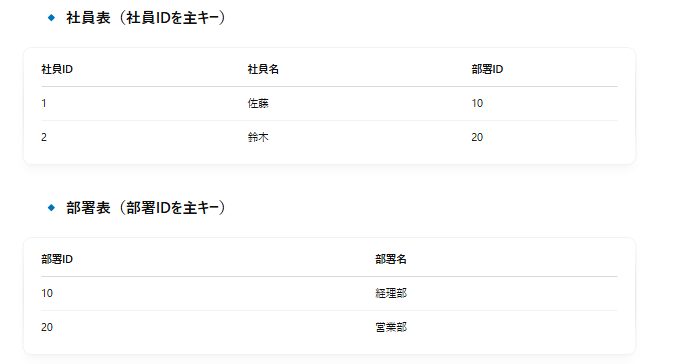
第3正規形になっていないことの問題点
① 更新時の不整合(Update Anomaly)
- 非キー項目が別の非キー項目に依存しているため、どちらか一方を更新したときに他と食い違う可能性があります。
例:
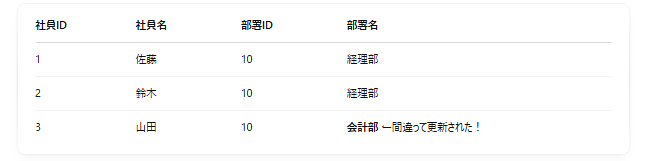
→ 「部署ID=10」の部署名が不一致になっていて矛盾が発生。
② 挿入時の問題(Insert Anomaly)
- 社員がまだ配属されていない部署を追加したい場合でも、「社員」がいなければ追加できません。
例: 「部署ID=30、マーケティング部」を作りたいけど、社員がいないので登録できない。
③ 削除時の問題(Delete Anomaly)
- 特定の社員を削除すると、その社員が所属していた部署の情報も一緒に削除されてしまうことがあります。
例: 社員ID=3(山田)を削除 → 部署ID=30の情報も消えてしまう。